Cuando se presentó C++11 hace más de 12 años, los amantes de C++ vimos cómo comenzaba una nueva era para el lenguaje, una modernización del mismo, y nos hizo tener que volver a estudiarlo (si es que alguien deja de hacerlo con C++), con ahora clásicos como el “Effective Modern C++” (Scott Meyers).
C++11 introdujo un montón de nuevas características, tales como templates variádicos, range-for, inicializadores de listas, inferencias de tipos (auto), constante nula real (nullptr), enumeraciones de tipo estricto (enum class), nuevos literales, multitarea (hilos, mutex), static_assert, constexpr, r-values, semántica de movimiento, funciones lambda, herencia de constructores, punteros inteligentes, especificadores de herencia override y final, expresiones regulares, tipos de enteros de tamaño fijo (int32_t, uint8_t, …), generadores de números aleatorios extensibles y type traits, entre tantos otros.
Como se ve, esta versión trajo multitud de mejoras tanto en su núcleo como en la biblioteca estándar, no sólo poniendo al día al lenguaje sino sentando las bases para futuras actualizaciones, que no ha parado desde entonces (se presentan nuevas versiones cada 3 años: C++14, C++17, C++20 y próximamente C++23).
Volviendo a la lista anterior, de entre todas las incorporaciones, una de las menos entendidas es la semántica de movimiento, no por su complejidad sino por confusión que genera, especialmente en los que recién comienzan a usar el C++ moderno. Veamos un poco de qué va eso del move.
Referencias rvalue
Primero decir que un lvalue es una expresión con nombre, a la que se le puede asignar un valor. Se llaman así porque suelen aparecer a la izquierda (left) de una asignación. Así, tenemos además referencias a lvalue (T&) y referencias constantes a lvalue (const T&, o T const& para los east-const).
Por el contrario, un rvalue es un temporal, un sin nombre, al que no se le puede asignar un valor. Lo que C++11 introduce entonces es el concepto de referencia a rvalue, con la sintaxis T&&. El punto central de todo esto está en que una referencia a rvalue puede ser modificada, sólo que como lo que se modifica es un rvalue, es decir, un temporal, podemos aprovecharnos de eso para hacer grandes optimizaciones.
Ejemplos
| Expresión |
Tipo |
a=1 |
a es lvalue, 1 es una constante |
a=b |
a y b son lvalue |
foo() |
El objeto devuelto por foo() es un rvalue |
a+b |
r-value |
std::move
Antes de proseguir, es importante comentar el segundo caso, donde aunque b está a la “derecha” de la igualdad, no es un rvalue, ya que (digamos) no es un temporal.
Con la función std::move podemos convertir una referencia a lvalue en una referencia a rvalue (si la referencia ya es a rvalue, no hay cambios). Nótese que esto no es más que una forma de forzar tipos de cara al compilador: std::move no tiene coste alguno a nivel de ejecución. De hecho, veremos, citando a Mayers, que std::move no mueve nada.
Constructores de movimiento
Así como en C++03 teníamos el constructor de copia (que recibe una referencia constante a lvalue, const T&), en C++11 se introduce el constructor de movimiento, que recibe una referencia a rvalue (T&&).
Así, una expresión como
std::string foo() { return "foo"; }
std::string bar{foo()};
llamaría al constructor de movimiento en lugar del de copia, porque foo() se interpreta como una referencia a rvalue.
Lo anterior parece una tontería, pero permite construir un objeto sacando partido de que sabemos que el argumento que recibmos es un temporal. Un ejemplo típico es el de los contenedores:
Tomemos como ejemplo un contenedor básico:
template<class T>
class MyVector {
T* m_data{nullptr};
size_t m_size{0};
public:
~MyVector() {
delete[] m_data;
}
explicit MyVector(const MyVector& o) {
if (o.m_size > 0) {
try {
m_data = new T[o.m_size];
m_size = o.m_size;
for (size_t ii = 0; ii < m_size; ++ii) {
m_data[ii] = o.m_data[ii];
}
} catch (...) {
delete[] m_data;
m_size = 0;
}
}
}
};
El constructor de copia tradicional (C++03) debería reservar por lo menos la misma cantidad de memoria que el vector de origen, y posteriormente copiar todos los elementos. Puede verse que ésta es una operación que tiene un coste, y dependiendo del tamaño del contenedor, éste puede ser alto. Si a esto añadimos que el argumento es un objeto temporal, tenemos que contar entonces con el destructor del objeto temporal y el hecho de que durante un tiempo hemos duplicado el consumo de memoria de esa función.
Un constructor de movimiento sabría que el objeto que recibe será destruido inmediatamente después (o por lo menos no se espera que siga siendo válido), por lo que podría, en lugar de reservar un nuevo bloque de memoria y copiar los elementos, simplemente intercambiar el puntero del nuevo objeto con el del temporal. Esto convierte una operación de orden lineal a una de orden constante (el sueño de todo optimizador). Además, el destructor del temporal sería una operación muy simple, ya que llamaría a un delete[] nullptr, que como sabemos no hace nada (y es legal, para los que no lo supiesen). Nuestro ejemplo anterior podría lucir así después de añadir un constructor de movimiento trivial:
template<class T>
class MyVector {
public:
// ...
explicit MyVector(MyVector&& o) {
std::swap(o.m_data, m_data);
std::swap(o.m_size, m_size);
}
};
Nótese el uso de std::swap; esto es debido a que el objeto pasado como referencia a rvalue aún existe y debe ser destruido al finalizar su tiempo de vida, por lo que si simplemente copiamos el puntero en o.m_data nos quedaríamos con un dangling pointer que llevaría a una violación de segmento al primer intento de acceso. No, debemos asegurarnos que el rvalue queda en un estado consistente y que su destrucción no afecte al objeto construido con él.
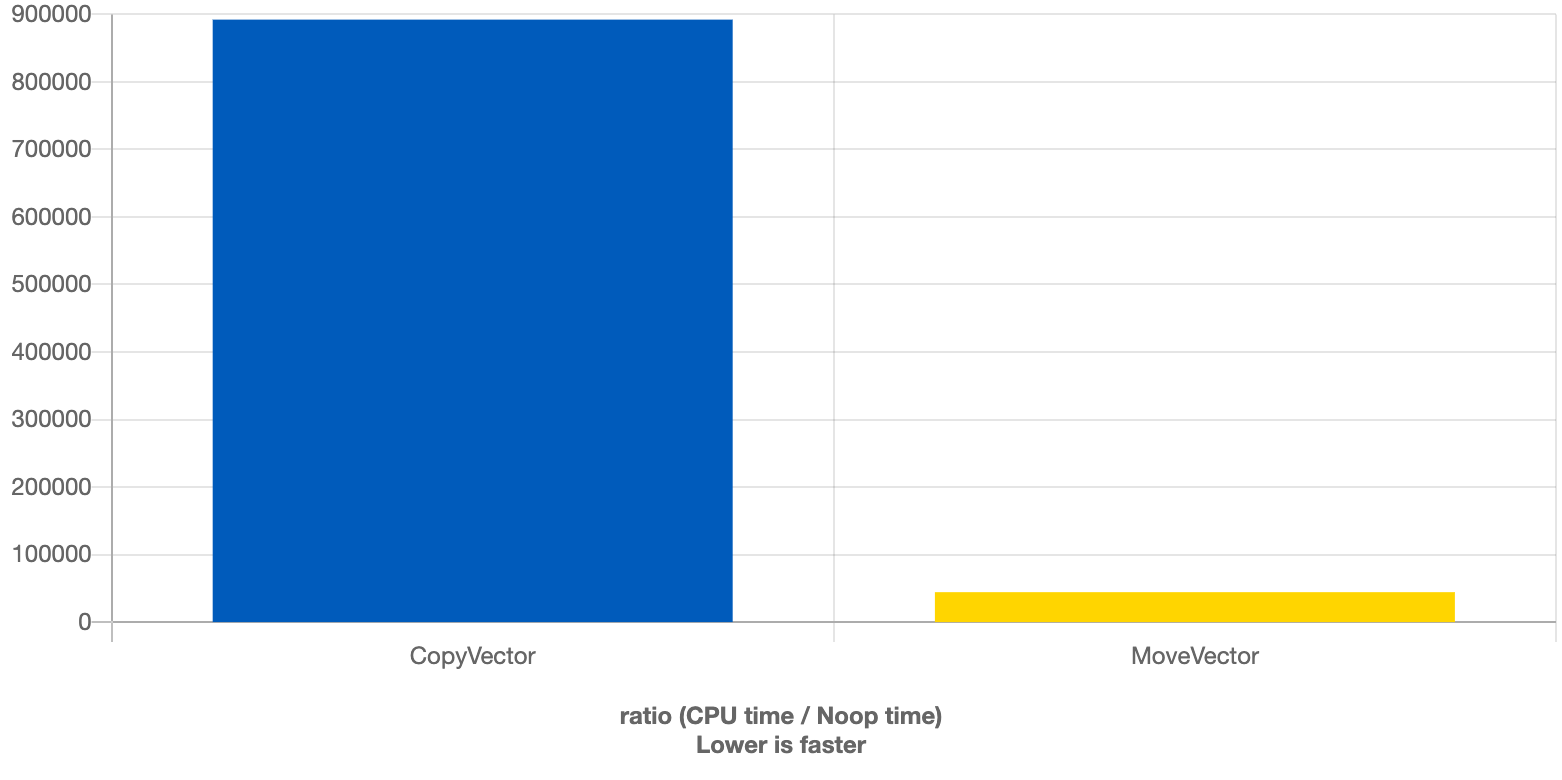
Como podemos imaginar de todo lo anterior, la diferencia de rendimiento es enorme, tal y como ejemplifica este benchmarking donde se compara la copia y el movimiento de un std::vector de 100.000 enteros (adjunto el código resumido):
constexpr size_t N{100'000};
void CopyVector() {
std::vector<int> v(N);
auto w = v;
}
void MoveVector() {
std::vector<int> v(N);
auto w = std::move(v);
}
Pero es que además hay algo aún mejor: todos los contenedores de C++11 han sido optimizados para sacar partido de la semántica de movimiento, por lo que solamente con actualizar a C++ moderno y recompilar es suficiente para aprovecharse de esta nueva optimización allá donde sea posible.
Para terminar esta sección, comentar de pasada que todo esto aplica además al operador de asignación, que desde C++11 tiene una nueva sobrecarga para aceptar referencias a rvalues:
T& T::operator=(T&& rhs) { ... }
No es oro todo lo que reluce…
…ni más rápido todo lo que pasa por std::move; y es que esta función realmente no mueve nada (S. Mayers). En cambio, solamente indica que se puede usar la semántica de movimiento, pero si dicha semántica no está implementada, o no puede sacar partido de las condiciones que rodean a ese rvalue, pues no obtendremos ventaja alguna.
Vimos antes que uno de los grandes beneficiados de la semántica de movimiento es la inicialización (o asignación) de contenedores a partir de referencias a rvalues, ya que podían sustituir una nueva reserva de memoria y la consiguiente copia (lineal), por un simple intercambio de valores.
De hecho, y esta es una pregunta que suelo realizar a muchos candidatos, si tuviésemos una estructura con 400 floats y añadiésemos un constructor de movimiento como el anterior, primero, no estaríamos mejorando nada, y segundo, ¡lo estaríamos incluso empeorando!: un constructor de copia realizaría 400 asignaciones, pero el de movimiento… ¡haría 1.200 (3 por cada swap)!
La semántica de movimiento sólo ayuda cuando somos capaces de ahorrar trabajo basándonos en el hecho de que el argumento va a ser destruido en cuanto acabe la operación. Si esto no nos aporta ninguna ventaja, entonces no ganamos nada.
Regla general
El movimiento de tipos básicos o de composiciones de los mismos no aporta ninguna ventaja frente a la copia.
Ahora bien, la presencia de punteros (incluyendo punteros inteligentes), es un claro indicador de que podríamos mejorar el rendimiento mediante la semántica de movimiento, si bien no reduciendo la complejidad algorítmica del mismo (como con los contenedores), al menos evitando las llamadas al sistema para reservar recursos.
Otros usos de la semántica de movimiento
Además de permitir optimizaciones, la semántica de movimiento juega un papel muy importante en la definición de tipos de datos no copiables. Pondré tres ejemplos tomados de C++11: std::thread, std::mutex y std::unique_ptr. Dado el objetivo de cada una de estas clases, la copia no tiene ningún sentido y, por ende, no debe estar permitida. ¿Qué es copiar un hilo: arrancar uno nuevo, copiar el estado actual? ¿Tiene sentido copiar un mutex que está garantizando un acceso exclusivo a un recurso? ¿No es contraditorio permit tener más de una copia de un objeto puntero único?
Por otro lado, debemos tener alguna forma en la que dichos objetos puedan ser trasladados de un lugar a otro (por ejemplo, como retorno de una función). Es acá donde la semántica de movimiento entra en juego proporcionando las condiciones para garantizar que los datos de estos objetos no se copian sino que se mueven de un objeto a otro.
Copy elision
No tiene una relación directa con la semántica de movimiento, pero se confunde con ésta alguna veces. El copy elision es una optimización que permite construir un objeto directamente en la dirección de memoria final de una expresión, omitiendo los constructores de copia intermedios. Por ejemplo, en:
T foo() { return T{}; }
T bar = T{T{T{foo()}}};
sólo se llamaría una vez al constructor por defecto, y directamente sobre la dirección de memoria de bar, en lugar de la cadena de constructores de copia (o movimiento) y destructores.
Es una optimización muy usada y, de hecho, es la única que viola la regla de as-if (se aplica la optimización aunque el constructor de copia o movimiento que se omiten tiene efectos secundarios).
Existen otras variantes, el RVO (Return Value Optimization) y NRVO (Named Return Value Optimization). La primera está garantizada (si se dan las condiciones el compilador no la puede obviar) desde C++17. Para más información sugiero consultar cppreference y algún hilo en Stack Overflow.
Conclusiones
La introducción de las referencias a rvalues es una de las principales mejoras introducidas en C++11 ya que asienta las bases para un nuevo tipo de optimizaciones de gran calado, así como la introducción de tipos de datos no-copiables fundamentales.
En este artículo hemos repasado brevemente su sintaxis y su impacto en el código, así como señalado las situaciones en las cuales no aporta mejora alguna, y en qué lo diferencia de algunas optimizaciones del compilador.
]]>