
Introducción
Como todos los lectores sabrán, C++ es un lenguaje compilado, lo que implica que su código fuente se transforma en un archivo binario ejecutable. No es necesario que el usuario final realice este proceso, lo hace el desarrollador. Generalmente es un proceso bastante rápido, pero a medida que el proyecto comienza a crecer también lo hace el tiempo requerido para su compilación. No es extraño encontrar proyectos de mediano tamaño que tardan 15-20 minutos en compilarse, y personalmente he trabajado con algunos que requerían unas 13 horas partiendo de cero.
Una de las primeras formas de reducir el tiempo de compilación usadas fue la de evitar compilar cosas que no fuesen necesarias: si un fichero ni ninguna de sus dependencias ni parámetros han sido modificados, una nueva compilación devolverá el mismo fichero objeto, por lo que una comparación de los timestamps entre ficheros fuente y objeto ayudará a centrarnos en aquellos que sí requieren ser procesados nuevamente. Este mecanismo es estándar en cualquier sistema de compilación, bien sean Makefiles, proyectos de MSVC, Xcode, etc.
Aún así, esto no suele ser suficiente, siendo frecuente tener que esperar entre 30 segundos y 5 minutos hasta que la compilación termine. Si sumamos el hecho de que tenemos que compilar multitud de veces cada día, en total supone un montón de tiempo dedicado a ver pasar líneas frente a nuestros ojos. Un día normal para mí conlleva entre 30 y 50 compilaciones, con una duración media de 30s, lo que nos da entre 15 y 25 minutos por jornada.

Casi todos aprovechamos estos micro-descansos durante las compilaciones para hacer algo en paralelo. Dos minutos apenas da tiempo para ir al baño, en 4 podemos hacernos un café (contando el tiempo de ir a la cocina, calentar la leche, etc.). Podemos aprovechar para responder un email o mirar el estado del equipo, etc. Pero, salvo contadas ocasiones, la experiencia dicta que es mejor no hacer nada, no sólo porque lo que creíamos que era cosa de 1 minuto se extienda, sino porque además hacer muchas cosas al mismo tiempo significa perder el enfoque: el cambio de contexto penaliza la tarea principal. Lo mejor que podemos hacer es tratar de minimizar ese tiempo muerto (obviamente estoy asumiendo que compilamos cuando lo necesitamos y no como tic nervioso).
En este artículo comentaremos algunas estrategias de optimización (todas centradas en reducir la cantidad de código a compilar, ya veremos por qué), cómo aplicarlas eficientemente, y aspectos a tener en cuenta para que no nos salga el tiro por la culata.
Poniendo a dieta al compilador
El proceso de compilación de proyectos en C++ se lleva a cabo, normalmente, en tres etapas: preprocesado, compilación y enlazado. Simplificando mucho, diremos que en la primera el fichero de código fuente es leído y convertido en un fichero de código fuente intermedio completamente autocontenido (es decir, que toda la información necesaria para compilarse está presente en dicho fichero). En la etapa de compilación, cada uno de estos ficheros autocontenidos es analizado y las sentencias C++ son transformadas en código binario intermedio, aunque aún no es ejecutable. Es en la tercera etapa donde todas las unidades de compilación son enlazadas entre sí junto a las dependencias externas, resultando en el fichero ejecutable.
Primero que nada, es importante mencionar que el preprocesado no hace ningún tipo de análisis de código; más bien podríamos verlo como una serie de operaciones de edición de texto. Por ejemplo, las macros son operaciones de sustitución de bloques de código (buscar/reemplazar), la inclusión de ficheros de cabecera es como un copiar/pegar, y la compilación condicional es como eliminación de código. Es durante la compilación donde se determina si el fichero tiene una sintaxis C++ válida y se identifica qué partes de todo el código compilado son realmente necesarias.
Como podemos intuir, la compilación más rápida será aquella que sólo compile lo que realmente estamos necesitando.
Análisis de la compilación
Es posible que muchos managers no entiendan el beneficio de reducir en 3 segundos el proceso de compilación. La forma más sencilla de justificarlo es, claramente, desde el punto de vista económico: 3 segundos por 30 veces diarias por 20 días al mes es media hora que gano al mes para el proyecto por programador. Lo mismo aplica para las pipelines de CI/CD.
De todas formas, si para conseguir esos 3 segundos hemos necesitado 3 días de trabajo, no hemos mejorado el proceso, ya que el ROI (Return on Investment) será muy bajo. Pero si por el contrario lo hemos hecho en una hora, habrá merecido la pena.
Se ve claramente que, como en toda optimización, lo primero que tenemos que hacer es averiguar dónde necesitamos optimizar, para atacar los problemas que nos den el mayor salto posible. Y es que casi siempre los cuellos de botella están centrados en unos pocos lugares.
Centraré la sección de profiling en clang, aunque el modus operandi en general es análogo en otros compiladores. Lo primero será activar la opción -ftime-trace, con la cual obtendremos un análisis de la compilación con el tiempo dedicado a cada etapa de la compilación y fichero (en MSVC sería /timetrace). El fichero generado se ubicará junto a los ficheros objeto intermedios, con el mismo nombre de la unidad de compilación pero extensión JSON. Podemos abrirlo con la herramienta de tracing incluida en cualquier navegador Chromium (por ejemplo, en Edge es edge://tracing/), o con otras como Perfetto (https://ui.perfetto.dev/).
Identificando objetivos
Hay básicamente dos formas que uso para detectar los cuellos de botella. La primera sería analizar los ficheros JSON manualmente, y lo que suelo hacer en estos casos es ordenarlos por tamaño y centrarme en los más grandes; si bien no siguen un orden estricto, en general un fichero JSON grande significa que el timetrace recolectó muchos datos sobre el mismo. La segunda ya es más elaborada, y pasa por un script que lee los JSON y básicamente ensambla estadísticas globales del proyecto, incluyendo ficheros de mayor tiempo (medio), número de inclusiones y tiempo total.
Personalmente uso una combinación de ambas: con el script obtengo una clasificación (el podio), los ficheros que más impactan la compilación. Luego los analizo manualmente, abriendo cualquiera de los JSON referenciados para su análisis.
La siguiente imagen muestra las trazas para la compilación de un fichero .cpp modesto, de 2K líneas y 68KB de peso (es un ejemplo real, por lo que he ocultado algunos datos). Los resultados se muestran como un flame graph: el eje horizontal es el tiempo desde el inicio del procesado del fichero, donde cada bloque es una fase de la compilación y su ancho es el tiempo invertido en dicha fase; el eje vertical es el call stack.
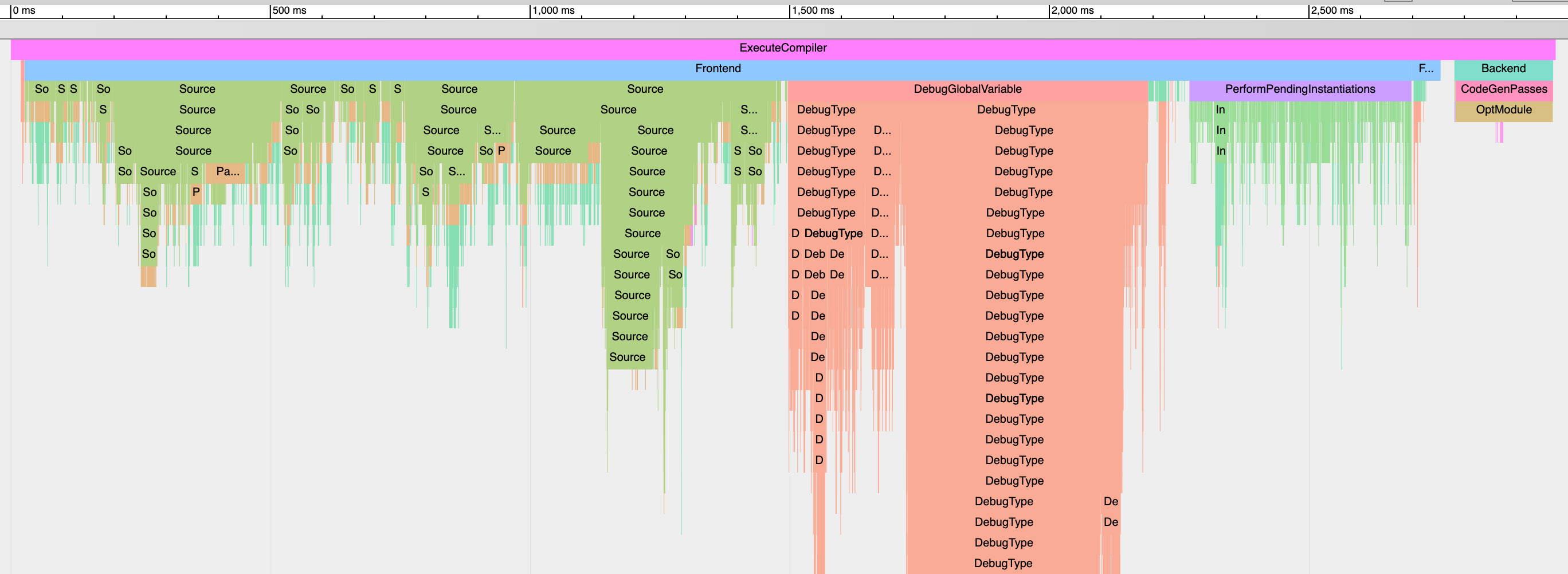
En este artículo nos centraremos en los bloques verdes, que representan la lectura, preprocesado y parseo (análisis sintáctico). Los bloques más grandes son nuestros principales cuellos de botella: ficheros que tardan mucho en ser analizados. Estos ficheros son los que tenemos que optimizar.
Ahora bien, debemos saber si, dado un bloque grande, el fichero asociado es pesado en sí mismo o porque otros (ficheros incluidos por el primero) lo engordan. Podemos obtener esta información en dos formas (complementarias entre sí): la primera es observar el eje vertical y el impacto de las dependencias (véase el bloque central: el primer fichero consume mucho, pero es obvio que es culpa de dos dependencias). La otra es observando los detalles de cada bloque (basta con seleccionar el bloque y ver el pánel inferior):

Acá podemos ver que si bien el procesado del fichero toma 325ms (wall duration), el fichero como tal solo toma 2ms (self time).
Esta combinación de acciones permite centrar los esfuerzos en los ficheros más importantes, si no podría pasar que el análisis individual sin ningún tipo de guía nos lleve a optimizar ficheros con un impacto muy bajo en la compilación final del proyecto.
Estrategias a seguir
A continuación comentaremos algunas de las acciones que podemos llevar a cabo para mejorar los tiempos de compilación, aunque podrían resumirse en quitar lo que no hace falta. El orden de exposición corresponde al que uso personalmente, siguiendo como criterio el tiempo que lleva aplicarlas.
- Incluir únicamente los ficheros de cabecera necesarios. Es normal que, a lo largo de la historia del proyecto, el código haya cambiado mucho, por lo que es posible que haya ficheros de cabecera innecesarios, o que estemos incluyendo un súper fichero que contiene muchas cosas cuando sólo necesitamos una. Cualquier limpieza viene bien, y más aún si es de alguno de nuestros objetivos. Esta estrategia puede no salir siempre bien en el caso de que otro fichero de cabecera del mismo documento esté incluyendo al que hemos borrado, con lo que no estamos ganando nada. Esta estrategia paga mejor cuando se aplica a limpiar los propios ficheros de cabecera de includes innecesarios, ya que el impacto se multiplica. Truco: algunos IDEs y analizadores estáticos proveen esta información de forma directa.
- Utilizar forward-declarations. Si nuestro fichero de cabecera sólo hace uso de una clase como una referencia o puntero (es decir, no necesita saber detalles), podríamos eliminar el fichero de cabecera que la declara y sustituirla por un forward declaration.
- Separar ficheros con múltiples declaraciones en ficheros individuales. Existe una regla de oro (aunque algo flexible) que dice que cada declaración debe ir en su propio fichero. Esto permite que incluyamos únicamente lo que necesitamos.
- Extraer declaraciones anidadas. Es una especie de corolario de la estrategia anterior: si una clase define una clase o enumeración dentro de la misma, cualquier referencia a los segundos obligará a incluir a la primera por completo.
- Utilizar el patrón Pimpl. No entraré en detalles, pero este patrón permite separar mejor la declaración de la implementación. Así no sólo evitamos incluir ficheros de cabecera que sólo son necesarios en la implementación, sino que además cualquier modificación en la misma no impacta a los ficheros que usan esta clase.
- Refactorizar las clases grandes en clases más pequeñas y con menos responsabilidades. De nuevo, una forma de incluir sólo lo que se necesita, pero que además mejora enormemente el diseño reduciendo el acoplamiento entre módulos.
Pasándonos de la raya
Consideremos ahora algunas posibles desventajas de las estrategias mencionadas:
- Un forward-declaration es un segundo lugar al que tenemos que prestar atención si hacemos algún cambio a un tipo de dato (especialmente su nombre) aunque normalmente esto implica únicamente un fallo de compilación.
- Tener decenas o cientos de mini-ficheros para definir enums puede ser tedioso de mantener; en algunas ocasiones bastará con tener unos pocos ficheros de “tipos” básicos, agrupados por componente o función.
- El uso del patrón Pimpl implica en la práctica una desreferencia de memoria adicional. En los sistemas modernos esto no suele ser un problema, pero convendría tenerlo presente si lo usamos en secciones de código donde el rendimiento es crítico (y el profiler ya nos ha dicho que el pimpl es el problema; no optimicemos prematuramente, primero el diseño).
Conclusión
Optimizar los tiempos de compilación no es sólo una cuestión de comodidad para el desarrollador, sino una inversión que mejora la productividad del equipo y reduce los costes del proyecto. Las estrategias presentadas en esta primera parte se centran en el principio fundamental de “compilar únicamente lo necesario”, atacando el problema en su origen: la cantidad de código que debe procesar el compilador.
La clave del éxito radica en medir antes de optimizar. Herramientas como -ftime-trace nos permiten identificar los verdaderos cuellos de botella y centrar nuestros esfuerzos donde realmente importa. No todos los ficheros tienen el mismo impacto, y una optimización bien dirigida puede resultar en mejoras significativas con un esfuerzo mínimo.
Recordemos que estas optimizaciones deben aplicarse con criterio: aunque las estrategias mencionadas son generalmente beneficiosas, siempre conviene evaluar el coste de mantenimiento frente a la ganancia obtenida.
El tiempo de compilación perdido nunca se recupera, pero el tiempo invertido en optimizarlo se amortiza cada día.