
Introducción
Trabajar con contenedores clave y clave-valor es algo que hacemos en casi cualquier aplicación: cachés, registros de configuración, índices, asociaciones entre datos… La biblioteca estándar de C++ nos proporciona varias opciones, cada una con sus fortalezas y debilidades. La opción obvia es std::set (para clave) std::map (para clave-valor), pero hay casos donde sencillas optimizaciones en estos contenedores pueden reportar ganancias significativas en rendimiento.
En este artículo compararemos algunos contenedores estándar, y buscaremos los mejores casos de uso para cada uno, así como sugerencias simples que mejorarán el rendimiento significativamente. Simplificaremos el estudio centrándonos en los contenedores clave-varlos (std::map y similares), pero en general las sugerencias y comparaciones son las mismas para los contenedores de conjuntos.
std::map: lo obvio
Cuando necesitamos un contenedor clave-valor ordenado, std::map es la primera opción que nos viene a la mente. Su API es directa: insert (emplace), find, contains, erase, clear, operator[]… Lo que ocurre internamente es que mantiene un árbol binario de búsqueda (típicamente un árbol rojo-negro), lo que garantiza que las claves siempre estén ordenadas y que operaciones como inserción, búsqueda y eliminación tengan complejidad O(log n).
std::map<std::string, int32_t> items;
items["key1"] = 42;
auto it = items.find("key1");
if (it != items.end()) {
std::cout << it->second << '\n';
}
Hay pequeños cambios que son sencillos de aplicar y que pueden darnos mejoras en nuestro código. Por ejemplo, usar emplace en lugar de insert o de operator[] (en este segundo caso debemos tener cuidado ya que emplace no reemplaza el valor si la clave ya existe).
El orden de las claves es útil cuando necesitamos iterar sobre ellas de forma ordenada, y la complejidad logarítmica es aceptable para la mayoría de casos. Pero hay un problema que no es evidente a primera vista.
El problema de la caché
std::map organiza los datos en un árbol disperso por la memoria. Cuando iteramos o realizamos búsquedas, los saltos entre nodos generan fallos de caché frecuentes. Tras un fallo de caché, el procesador debe esperar (típicamente unos cientos de ciclos) para obtener la siguiente línea de caché desde memoria principal. En una búsqueda logarítmica sobre millones de elementos, estos fallos se acumulan.
Comparemos esto con un contenedor lineal en memoria: cada acceso tiende a cargar datos vecinos útiles. Es el fenómeno conocido como locality of reference.
El problema de los destructores
Imaginemos ahora otro escenario común: tenemos una función que crea un std::map, lo llena, lo usa y luego lo destruye. Si esta función se invoca frecuentemente (miles de veces por segundo), ¡el destructor se convierte en un punto caliente! El destructor debe:
- Liberar la memoria de cada nodo
- Llamar al destructor de cada clave
- Llamar al destructor de cada valor
Todo esto ocurre de forma dispersa en memoria. En aplicaciones con requisitos de latencia baja o rendimiento crítico, esto es problemático.
std::vector<std::pair<K, V>>: la opción contrarreformista
¿Y si simplemente usáramos un vector ordenado de pares? Podríamos insertar todos los elementos, luego ordenarlo una única vez (ver detalles al final del artículo) y a partir de ahí realizar las búsquedas usando std::lower_bound. Siempre que no necesitemos encontrar elementos mientras insertamos, esta estrategia tiene ventajas interesantes.
La complejidad de búsqueda sigue siendo O(log n), como en std::map, pero con el beneficio en la caché que proporciona un array contiguo. La latencia de fallos de caché es varios órdenes de magnitud menor. La inserción de elementos es prácticamente gratuita (es un emplace_back, o mejor aún si hemos podido reservar toda la memoria de antemano con reserve), y toda la memoria se libera de una sola vez.
Como contrapartida, si necesitamos búsquedas mientras insertamos, o si modificamos y reordenamos constantemente, los costes se disparan. Pero para el patrón de “llenar, buscar, destruir”, este enfoque es extraordinariamente eficiente.
Además, la destrucción de este contenedor es mucho más eficiente, ya que no hay que recorrer multitud de nodos dispersos en memoria, sino que se realiza una única liberación de memoria al final.
std::map vs std::vector ordenado
Resumiendo la comparación principal del artículo:
std::map<K, V>mantiene orden e inserciones/búsquedas dinámicas en O(log n), pero paga con peor localidad de memoria y más coste en destrucción.std::vector<std::pair<K, V>>ordenado también permite búsquedas en O(log n) tras ordenar, con mucha mejor localidad y destrucción más barata.- Si el patrón es “insertar todo -> ordenar -> consultar”,
vectorsuele ganar claramente. - Si necesitamos mantener el orden y consultar mientras vamos insertando,
std::mapsigue siendo la opción natural.
Potencia amplificada: vector<pair> con PMR
C++17 introdujo memory resources (PMR). La idea es simple: en lugar de permitir que cada vector asigne su propia memoria, podemos proporcionarle un resource que gestiona dónde y cómo se asigna dicha memoria.
std::pmr::unsynchronized_pool_resource pool;
std::pmr::memory_resource* resource = &pool;
{
std::pmr::vector<std::pmr::pair<std::string, int32_t>> items(resource);
// use the vector
}
El beneficio es significativo cuando el patrón es realmente frecuente. No sólo evitamos nuevas asignaciones (lo que libera presión en el allocator), sino que la latencia se regulariza porque la memoria ya está “caliente” en caché.
Nota: Si se usa C++14 o anterior, o el compilador no soporta PMR, siempre podemos recurrir a Boost.PMR, que contiene una implementación muy parecida.
Coletilla: std::unordered_map si no necesitas orden
Si el orden de las claves no es relevante, std::unordered_map es una opción normalmente mejor que std::map (aunque no siempre mejor que el vector ordenado). Usa una tabla hash internamente, lo que reduce la complejidad de búsqueda a O(1) en promedio (en el caso de usar cadenas de caracteres como clave, la complejidad suele ser O(m)).
std::unordered_map<std::string, int32_t> items;
items.emplace("key1", 42);
auto it = items.find("key1");
Aun así, el rendimiento real depende de la función hash y de la distribución de las claves. Cuando se usan cadenas de caracteres como clave, normalmente se habla de que la función hash es O(m), donde m es la longitud de la clave, es porque calcular el hash obliga a procesar todos los caracteres de la clave. Además, igual que std::map, no elimina por sí mismo el coste de destruir claves y valores si el contenedor se crea y destruye continuamente, aunque el overhead de destruir el contenedor como tal es menor ya que no está disperso en memoria.
Benchmarks
Sin entrar en grandes comparativas, a continuación mostramos una comparativa entre los tres contenedores mencionados en este artículo. En este experimento creamos N elementos aleatorios (la clave puede repetirse), buscamos N valores aleatorios, y luego destruimos el contenedor. Usamos 3 casos (de arriba a abajo): N = 10K, N = 100K, N = 1M.
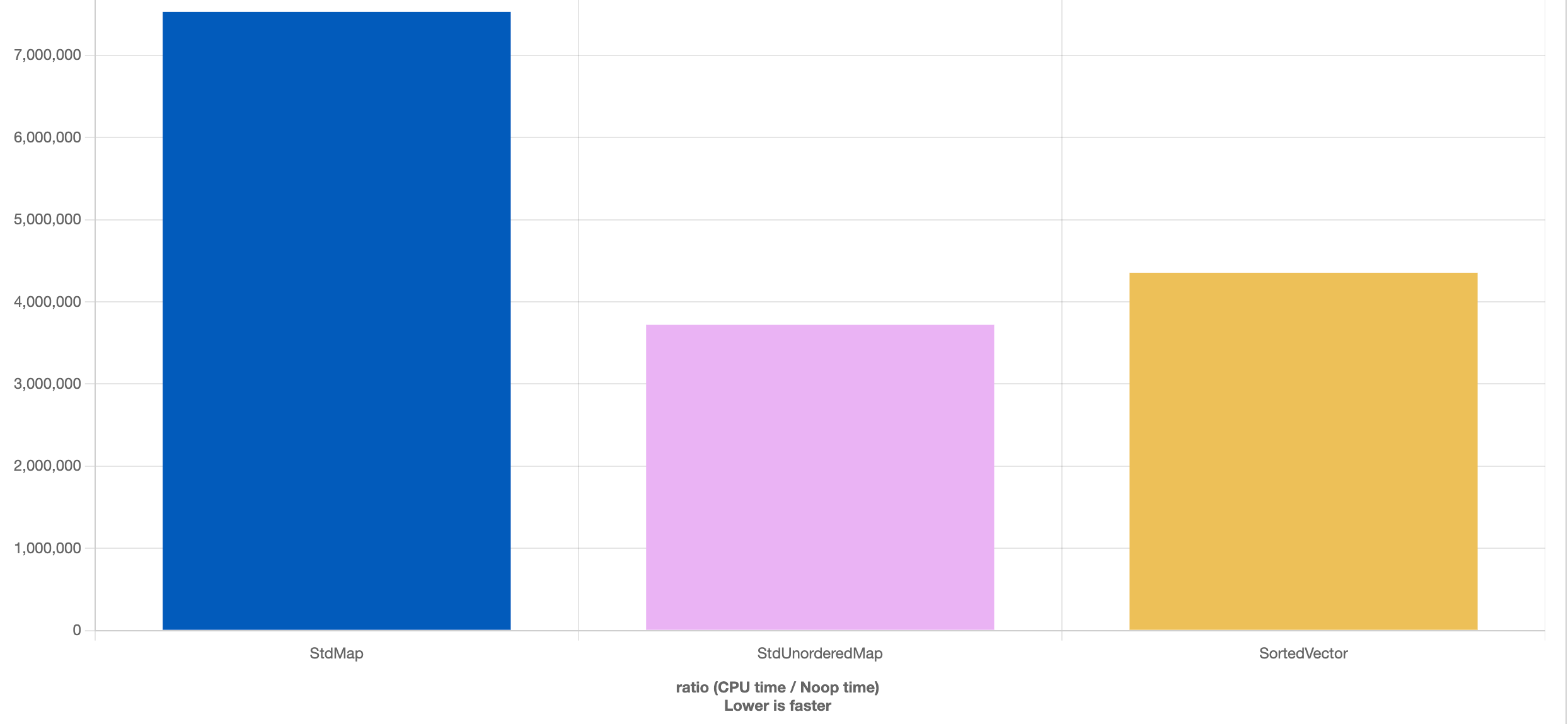
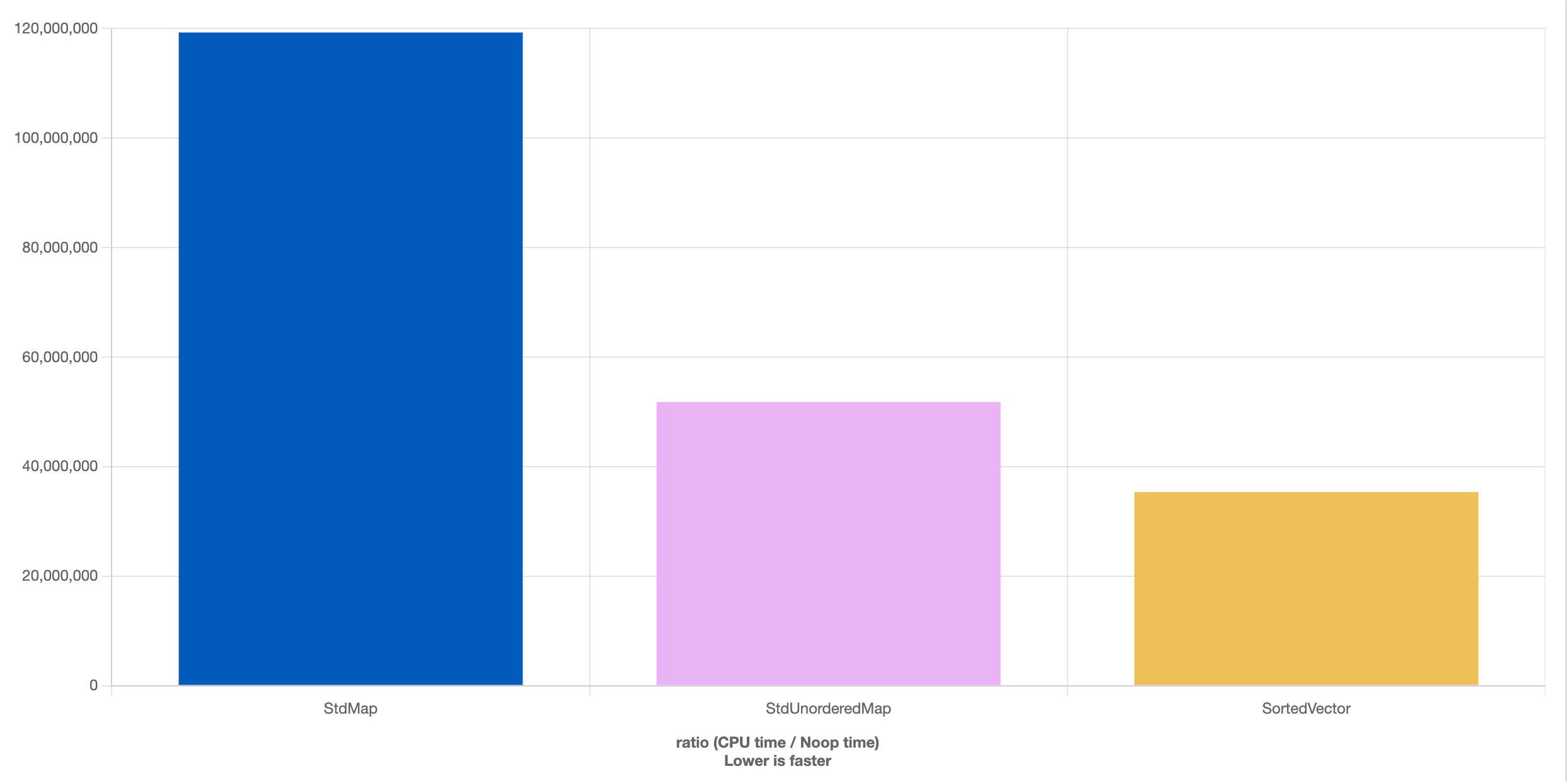
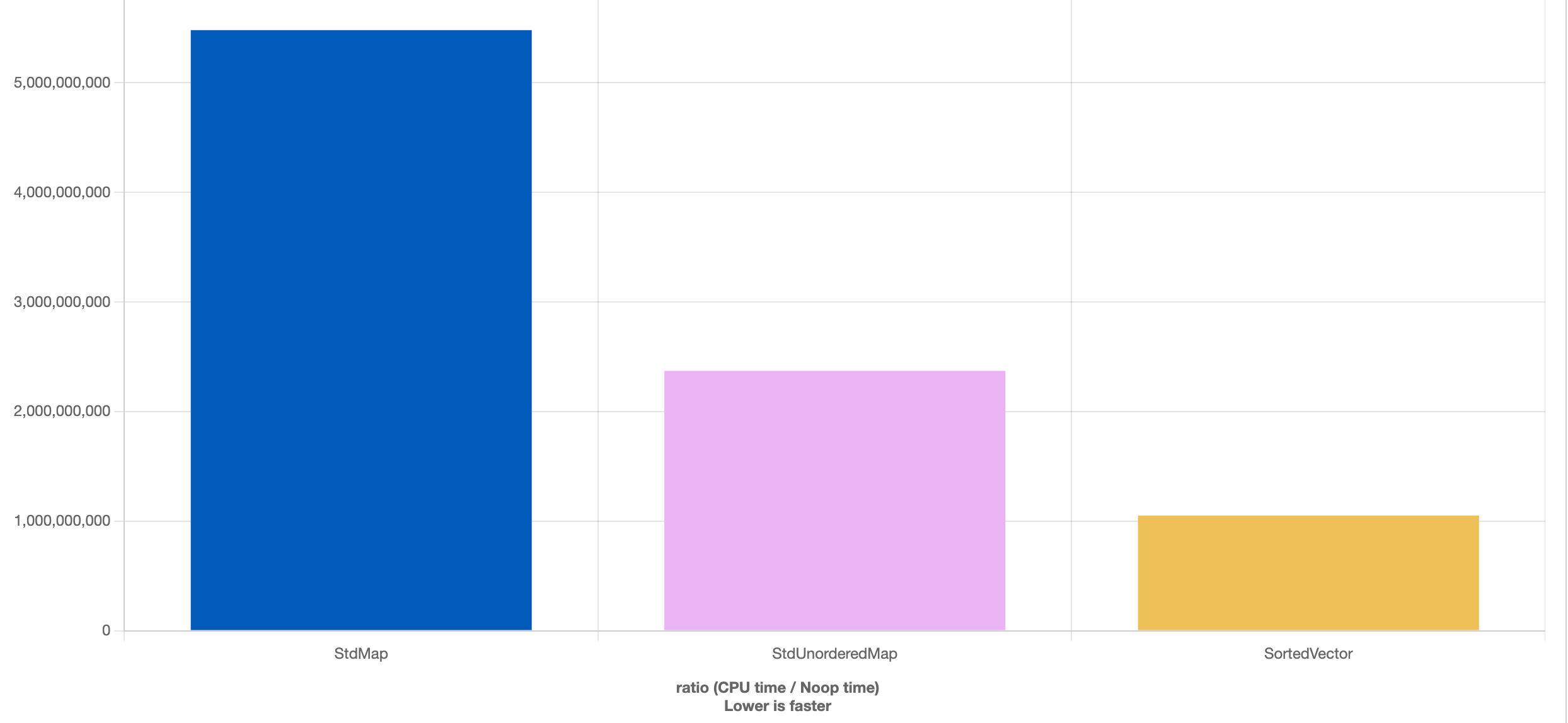
Podemos como el std::vector ordenado es más eficiente que los dos contenedores estándar cuando el número de elementos aumenta, lo que nos muestra la importancia de considerar la caché en nuestras optimizaciones.
Bonus: lo mismo aplica a std::set
Como mencionamos al principio, todo lo anterior es directamente aplicable a std::set y std::unordered_set. El razonamiento, las optimizaciones y los trade-offs son idénticos; simplemente sin el componente “valor”.
Conclusiones
La elección del contenedor clave-valor adecuado requiere entender más allá de la complejidad asintótica. Los detalles de memoria, caché y ciclo de vida del objeto son relevantes. En muchos casos, una solución “ingenua” resulta más eficiente que la opción obvia porque juega mejor con las características del hardware moderno.
La recomendación genérica sigue siendo: medir antes de optimizar. Pero si identificamos que un contenedor clave-valor es cuello de botella, empezaremos por considerar si afecta en realidad al caché, y si el contenedor tiene vida corta; si es así, vector<pair> ordenado probablemente sorprenderá.
Apéndice: ordenando std::vector
Al ordenar el std::vector debemos tener en cuenta la forma en que se comporte la inserción de elementos en un std::map: si se inserta un elemento con una clave ya existente, el valor se reemplaza. Para expresar esto en nuestro patrón insertar luego ordenar debemos primero mantener el orden de inserción durante el ordenamiento, y luego quedarnos con el último elemento del grupo que use la misma clave.
std::vector<std::pair<std::string, int32_t>> items;
// (Insert data here)
// Sort, keeping insertion order
std::stable_sort(items.begin(), items.end(), [](const auto& a, const auto& b) {
return a.first < b.first;
});
// Remove duplicates and keep last one
auto it = std::unique(items.rbegin(), items.rend(), [](const auto& a, const auto& b) {
return a.first == b.first;
});
items.erase(items.begin(), it.base());
// Binary searches
auto it = std::lower_bound(items.begin(), items.end(), "key1",
[](const auto& a, const auto& b) { return a.first < b.first; });